Understanding Vector Databases: The Backbone of Modern AI Retrieval
In the world of AI and machine learning, the amount of unstructured data is exploding—text, images, videos, and more. But how can an AI system effectively retrieve the most relevant pieces of information? This is where vector databases come into play.
The featured image above provides a great visual explanation of the process:
- Content: This represents any data we want to process and retrieve—whether it’s a document, image, or video.
- Embedding Model: When a query (e.g., a question or search term) is made, the data first passes through an embedding model. Embeddings are numerical representations of content, mapped into high-dimensional vectors. For example, the phrase “AI applications in healthcare” might get converted into a vector like
[0.34, -1.2, 1.3, … -0.03, 1.4]. This transformation helps the system understand the context and meaning of the content in a way that numbers can represent. - Vector Embedding: Once the content is converted into a vector, it’s stored in a vector database. This type of database is different from traditional relational databases that rely on rows and columns. Instead, vector databases store vectors and enable efficient similarity searches.
- Vector Database: As the image shows, a vector database holds a collection of vectors (shown as yellow dots). When a new query comes in, it is also converted into a vector, and the database performs a search by calculating the similarity between vectors—typically using metrics like cosine similarity or Euclidean distance. The closer the vectors are in space, the more similar the content.
- Query Result: The system returns the most relevant content based on vector proximity. This enables AI systems to answer questions, recommend items, or retrieve documents with much greater accuracy than traditional keyword-based searches.
In essence, vector databases power applications that need fast, efficient retrieval of highly complex, unstructured data. Whether for AI chatbots, recommendation systems, or search engines, vector databases are crucial in enabling context-aware retrieval and understanding across vast datasets.
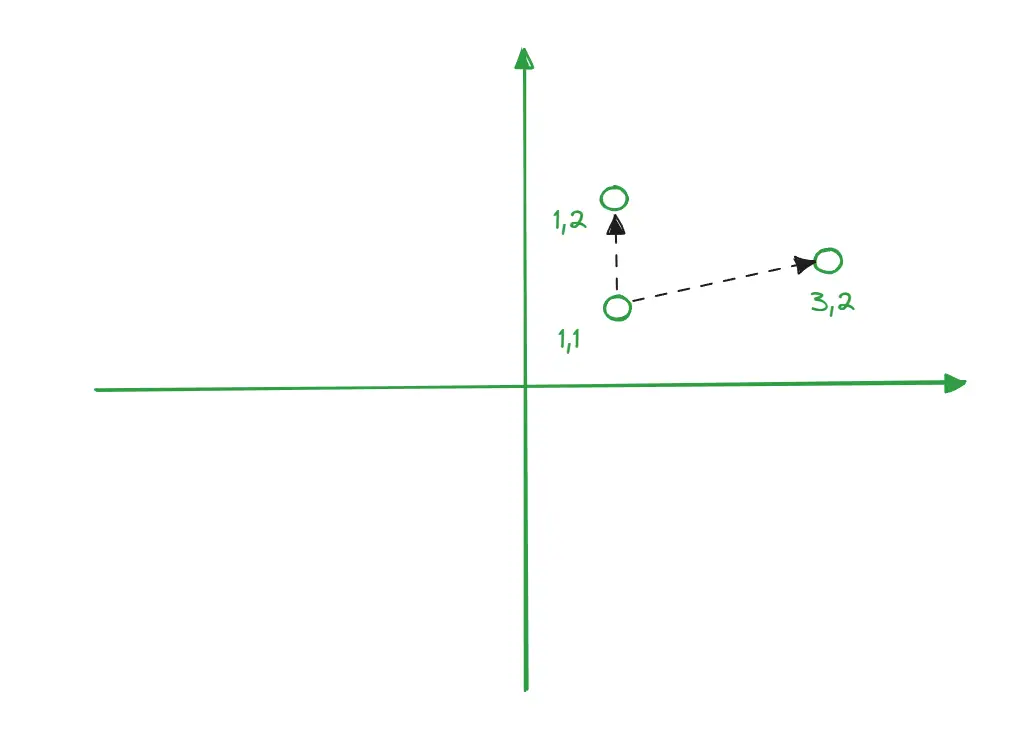
Understanding Cosine Similarity with Vector Spaces
In this diagram, the points represent vectors in a two-dimensional space, with coordinates (1,1), (1,2), and (3,2). These vectors can be thought of as pieces of information in a vector database, similar to how text or data is represented.
Cosine similarity measures how similar two vectors are by calculating the cosine of the angle between them. Unlike Euclidean distance, which measures the absolute distance between points, cosine similarity focuses on the direction of the vectors rather than their magnitude.
In the example:
- The vectors from (1,1) to (1,2) and from (1,1) to (3,2) form angles.
- Cosine similarity would compare these angles, showing that vectors with smaller angles (closer to 1) are more similar.
In AI applications, cosine similarity is commonly used for comparing text embeddings, ensuring that queries return the most contextually relevant results by comparing the directional alignment of their vectors.
At Dolphin Studios LLC, we specialize in integrating vector databases with advanced AI models to enhance data-driven applications, allowing businesses to unlock deeper insights and create more intelligent systems. By leveraging tools like self-hosted or third-party vector databases (e.g., Pinecone), we can deploy AI solutions that sift through mountains of information with ease and precision.